
Amazon Data Pipeline (DPL) is late entrant to the ETL market but provides many features that are well integrated to AWS cloud. In any data extraction process one would encounter invalid or incorrect data and that data may either be logged or ignored depending on the business requirements or severity of rejected data.
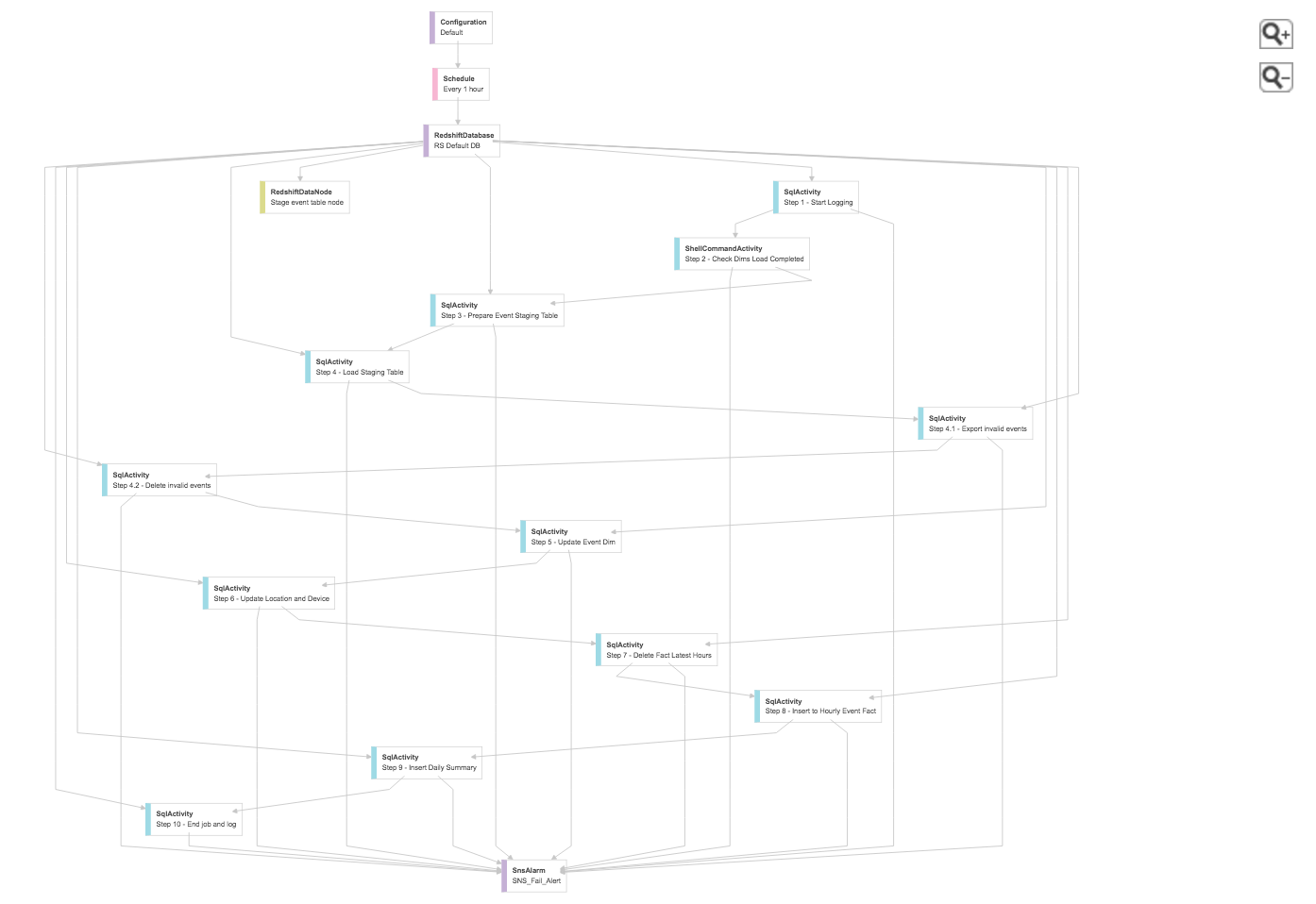
When you have your data flow through S3 to other platforms, be it, Redshift, RDS, DynamoDB, etc. in AWS you can use S3 to dump that data. In an example, similar to one DPL below, in one of the step you could filter and dump to S3 for later analysis.

By standardizing the rejections from different DPLs, another DPL can regularly load them back into Redshift for quick realtime analysis or deep dive into them downstream. This will also greatly help in recovery and reruns when needed.
Following is simple high level steps where rejected data is directed to S3. The parameters are provided through the environment setup. For example: #{myDPL_schema_name} = 'prod_public' and #{myDPL_error_log_path} = 's3://emr_cluster/ad/clicks/...'
When you have your data flow through S3 to other platforms, be it, Redshift, RDS, DynamoDB, etc. in AWS you can use S3 to dump that data. In an example, similar to one DPL below, in one of the step you could filter and dump to S3 for later analysis.
By standardizing the rejections from different DPLs, another DPL can regularly load them back into Redshift for quick realtime analysis or deep dive into them downstream. This will also greatly help in recovery and reruns when needed.
Following is simple high level steps where rejected data is directed to S3. The parameters are provided through the environment setup. For example: #{myDPL_schema_name} = 'prod_public' and #{myDPL_error_log_path} = 's3://emr_cluster/ad/clicks/...'
-- PreProcess
-- Load staging stable and at the same time update data error column in it when possible.
INSERT INTO #{myDPL_schema_name}.#{myDPL_staging_table}
SELECT col1,
col2,
col3,
etc
CASE WHEN
AS data_error
FROM #{myDPL_schema_name}.#{myDPL_source_table}
LEFT OUTER JOIN #{myDPL_schema_name}.table_1
ON ...
LEFT OUTER JOIN #{myDPL_schema_name}.dim_1
ON ...
LEFT OUTER JOIN #{myDPL_schema_name}.dim_N
ON ...
WHERE ...
-- OR, If data_error column is updated separately...
UPDATE #{myDPL_schema_name}.{myDPL_staging_table}
SET data_error = ...
FROM #{myDPL_schema_name}.{myDPL_staging_table}
JOIN #{myDPL_schema_name}.dim_1
JOIN #{myDPL_schema_name}.dim_N
WHERE ...
-- Temporary table
CREATE TEMP TABLE this_subject_dpl_rejections AS (
SELECT
...
FROM #{myDPL_schema_name}.#{myDPL_staging_table}
WHERE data_error IS NOT NULL
);
-- Dump to S3
UNLOAD ('SELECT * FROM this_subject_dpl_rejections')
TO '#{myDPL_ErrorLogPath}/yyyy=#{format(@scheduledStartTime,'YYYY')}/
mm=#{format(@scheduledStartTime,'MM')}/dd=#{format(@scheduledStartTime,'dd')}/
hh=#{format(@scheduledStartTime,'HH')}/ran_on_#{@actualStartTime}_file_'
CREDENTIALS 'aws_access_key_id=#{myDPL_AWSAccessKey};aws_secret_access_key=#{myDPL_AWSSecretKey}'
GZIP
PARALLEL OFF
ALLOWOVERWRITE;
Now load the errors back to Redshift...COPY #{myDPL_schema_name}.#{myDPL_error_table}
FROM '#{myDPL_ErrorLogPath}/yyyy=#{format(@scheduledStartTime,'YYYY')}/
mm=#{format(@scheduledStartTime,'MM')}/dd=#{format(@scheduledStartTime,'dd')}/
hh=#{format(@scheduledStartTime,'HH')}/'
CREDENTIALS 'aws_access_key_id=#{myDPL_AWSAccessKey};aws_secret_access_key=#{myDPL_AWSSecretKey}'
DELIMITER '|'
GZIP
TRIMBLANKS
TRUNCATECLUNS
IGNOREBLANKLINES
